

Key Takeaways
- AI bots visit your site for three distinct reasons: to train LLMs, to index content for AI search citations, and to act as autonomous agents performing tasks.
- Blocking all AI bots indiscriminately risks removing your brand from AI search results. By the same token, allowing unrestricted crawling can strain server performance.
- The balanced approach is selective control: rate-limit heavy crawlers, keep indexing bots like GPTBot accessible.
- Thanks to the UK CMA ruling in June 2026, websites are now allowed the opportunity to opt out of AI Overviews while staying in standard Search results.
- Your hosting provider or CDN may already be blocking AI bots at the server level, even if your robots.txt says otherwise.
- Use SUSO’s AI Search Visibility Checker to verify which bots can actually access your site.
For years, website optimization has centered on catering to search engine crawlers, such as Googlebot. These bots index and understand your content, forming the bedrock of your organic search visibility.
Now, we have a new species of bot in the ecosystem. These AI bots, from major players like Google, Microsoft, OpenAI, and others, are not just indexing for traditional search results.
They are gathering data to train their models, answer user queries directly in AI-powered search results, and generate summaries that could either drive traffic to your site or, conversely, answer the user’s question without them ever needing to click through.
This shift has created tension. On one hand, these bots represent a new frontier for content visibility and audience reach. On the other hand, they introduce concerns about content scraping and a potential loss of traffic.
What Are AI Bots and How Do They Work?
AI bots are sophisticated software programs designed to crawl the web autonomously. Unlike traditional search engine crawlers, their purpose isn’t solely to create a search index.
AI bots analyze, understand, and extract information from web pages to train large language models (LLMs), generate conversational responses, and provide summarized answers to user queries.
AI bots work by crawling, parsing, and synthesizing data, a bit like traditional crawlers, but their goal is to generate answers, not just index pages.
Filip Ruprich, Chief Performance Officer
While some AI bots belong to major search engines and integrate with traditional SEO, others operate independently, gathering data for a wide range of applications from chatbots to data analysis tools. This dual function is what makes them both a potential ally and a source of concern for website owners.
There are three distinct categories to be aware of:
- Training bots (Scraping). These crawl the web to harvest data for LLM development, gathering text in bulk over time to improve model quality. GPTBot, CCBot, and many lesser-known scrapers fall into this category. Contrary to common belief, their visits don’t result in citations or traffic; they are building tomorrow’s AI, not indexing today’s content.
- Indexing bots (AI Search). These crawl in real time to surface relevant citations in AI search responses. Think Google’s AI Overviews, Bing’s Copilot, or ChatGPT’s search mode. Blocking these bots means your content won’t appear as a cited source when users ask AI-powered search tools questions you could answer.
- Agentic bots (Action). A newer and rapidly growing category. These bots perform tasks on behalf of users: browsing, comparing, purchasing, and summarising. They don’t just read your site; they interact with it.
Agentic bots are the category most site owners simply aren’t prepared for, and they are growing fast. The implications for e-commerce and content-heavy sites are absolutely huge. For a detailed breakdown, see our article on what agentic browsers mean for SEO.
Which AI Bots Are Crawling Your Website?
A range of AI bots crawl the web for different purposes. The most prominent are transparent about their identity, using specific user-agent strings that you can identify in your server logs. Key players include:
- GPTBot: OpenAI’s primary crawling bot, used for both training and search indexing
- Google-Extended: Google’s user-agent token for controlling Gemini and Vertex AI training access
- CCBot: Common Crawl’s bot, widely used to build open training datasets
- OAI-SearchBot: OpenAI’s dedicated search indexing crawler
- Anthropic’s ClaudeBot: used to train and improve Claude

Alongside these, dozens of smaller, less transparent scrapers operate across the web, though many lack clear documentation or an obvious, identifiable purpose. Those unnamed, undocumented scrapers are the ones most worth filtering aggressively.
Understanding which bots are accessing your site is the first step in deciding on a blocking strategy, as it allows you to differentiate between legitimate players and those that may be operating without a clear purpose or with malicious intent.
AI Bots and Website Performance: What the Data Shows
An analysis of 68 million AI crawler visits published by Search Engine Journal found that most AI crawling is now tied to real-time answer retrieval rather than model training.
Fetch activity accounts for 56.9% of all crawler visits (driven almost entirely by ChatGPT), while training crawls account for 28.8% and content indexing accounts for the remaining 14.3%.
The same research found that LLM referral traffic has increased sharply year-on-year across multiple platforms, strongly indicating that AI-generated discovery is a growing source of real traffic, and not a marginal one.
The implication is clear: blocking the bots behind that 56.9% means opting out of the fastest-growing discovery channel on the web.
SEO Agencies and the Shift to AI Search Strategy
AI bots present a complex challenge for SEO agencies, forcing them to re-evaluate their strategies and client communications. A growing number of site owners are looking to block AI websites and crawlers entirely, but agencies need to help clients understand that a blanket approach carries real risks.
Clients in a wide range of industries, from software development to public relations, are increasingly concerned about the implications.
Their worries often revolve around the potential for content scraping and how it might devalue their original content, as well as the risk of losing direct website traffic if an AI bot answers a user’s query without a click-through. It’s why so many site owners want to block AI websites altogether.
The Trade-Off Between Protection and Visibility
For SEO agencies, this means a shift from traditional keyword optimization to a more holistic approach focused on AI Search and Generative Engine Optimization. This new approach also requires SEO agencies to educate clients about the shifting search environment, providing them with a clear understanding of the risks and opportunities associated with AI bots.
Agencies are now tasked with implementing technical measures, such as adjusting robots.txt files and the new llms.txt files to control bot access. This is in addition to developing content strategies that cater to traditional search engines and position the client as a verifiable, expert source for AI-generated summaries.
Who Blocks AI Bots and Why?
Industries most likely to block AI bots are those where content is a core business asset, such as news media, publishing, and other content-driven businesses. The primary reasons for blocking AI bots are:
- to protect valuable intellectual property from being used to train AI models without compensation or attribution
- to prevent a loss of organic traffic and revenue when AI provides direct answers
- to manage server performance and avoid resource strain from excessive scraping
While the robots.txt file is the simplest method, it’s not foolproof, as malicious bots can ignore it. Many employ more robust solutions, like web application firewalls and server-side blocking, to gain more control over their content and data.
Why Certain Industries Block AI Bots
Many companies are limiting bot access to protect their data, revenue, and users.
Publishing & Media
To protect intellectual property and maintain ad revenue. Publishers want traffic on their sites, not redirected to AI.
Examples: The New York Times, Associated Press, Reuters.
Ecommerce
To shield unique product descriptions and pricing from competitors and data scraping tools.
Examples: Amazon and major retail platforms.
User-Generated Content
To protect community-created content and licensed data from unrestricted scraping that could devalue their asset.
Examples: Reddit.
High-Authority Data Sites
To control access to specialized, research-based content in sensitive industries like law, medicine, and finance.
Examples: Scientific, medical, legal, and financial websites.
How to Block AI Bots (Without Killing Your SEO)
There are several layers of control available, each with different trade-offs.
How to Prevent Bots from Crawling Your Site: robots.txt
The most common method for blocking AI bots is through the robots.txt file, a text file that provides directives to web crawlers. By adding specific lines, such as User-agent: GPTBot followed by Disallow: /, you can request that a bot refrain from crawling certain parts of your site.
Robots.txt is a polite request, not a security gate. If you truly want to keep AI bots out, you’ll need to go beyond simple directives and implement server-side blocks or a WAF for real control.
Filip Ruprich, Chief Performance Officer
However, this method is merely a request and is not legally or technically binding. While reputable bots will honor these directives, malicious or unethical bots may simply ignore them.
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /Note: To opt out of Gemini training specifically, the Google-Extended user agent entry is all you need.
Web Application Firewalls (WAFs) and Server-Side Rules
For a more robust solution, website owners can implement web application firewalls (WAFs) or use server-side blocking rules based on a bot’s IP address or user-agent string. These methods offer greater control but require more technical expertise and ongoing management. It’s the only reliable method for blocking bots that ignore robots.txt entirely.
Cloudflare
Cloudflare has become a major gatekeeper in the AI bot conversation and warrants its own section.
In July 2025, Cloudflare changed its default behaviour to automatically block AI crawlers across its client sites, a move reported by MIT Technology Review. This was significant: millions of websites became invisible to AI indexing bots overnight, without their owners necessarily realising it.
Since then, Cloudflare has introduced more granular controls, including a dedicated AI bot management interface that lets you allow or block individual bots by name. More recently, the company launched Markdown for Agents, a feature that serves your content in clean markdown format specifically for agentic AI clients, treating them as a distinct channel rather than a threat to be blocked.
The broader message from Cloudflare’s evolution is instructive: the industry is moving from blanket blocking toward selective control. You should be too.
If your site runs behind Cloudflare, check your AI bot settings now. The default configuration may be blocking bots you actually want crawling your content.
Amazon and the eCommerce Dilemma
Amazon’s handling of AI bots illustrates the tension facing ecommerce at scale. The platform has taken steps to restrict AI shopping agents, bots that can browse product listings, compare prices, and complete purchases autonomously on behalf of users.
The concern is straightforward: if an agent handles the entire purchase journey, Amazon loses the data, the session, and potentially the sale.
But as CNBC reported in late 2025, Amazon faces a genuine dilemma to fight agentic AI or build its own. Blocking agents entirely may simply redirect users to competitors who have embraced the channel. For smaller ecommerce operators, the practical question is similar: do you block agents from browsing your product catalog, or optimize for them?
Hosting as the Hidden Gatekeeper
Here’s a blind spot that’s catching site owners off guard: your hosting provider may already be blocking AI bots at the infrastructure level, regardless of what your robots.txt says.
Many CDNs and managed hosting platforms have quietly introduced server-level AI crawler blocks to save bandwidth. The result is that your robots.txt may allow GPTBot, but the bot never reaches the server.
This is a primary reason why verifying AI visibility through a technical audit (rather than simply reviewing your robots.txt) has become essential. What your directives say and what bots actually experience can be two very different things.
AI Bots and Server Performance
The relationship between AI bots and website performance is one of the most underestimated issues in technical SEO right now.
Unmanaged AI crawling can spike CPU usage and memory consumption, particularly from scrapers that ignore crawl rate conventions entirely. Unlike Googlebot, many AI training scrapers have no such restraint. This is where teams consider blocking AI traffic entirely, but that’s rarely the right call.
Rate-limiting is a more precise instrument. For bots that generate citations and drive traffic (GPTBot, for example), you want them to crawl, just not hammer your server at 3 am. Most WAF configurations allow crawl rate limits per user-agent, giving you performance protection without sacrificing AI search visibility.
Teams that block AI traffic indiscriminately often discover the problem too late, only when rankings drop. Monitor your server logs regularly: a sudden spike from unrecognised user-agent strings is a reliable indicator that unethical scrapers are active.
Google Publisher Controls and Google-Extended
This is where things get genuinely complex, and where much of the current SEO advice oversimplifies.
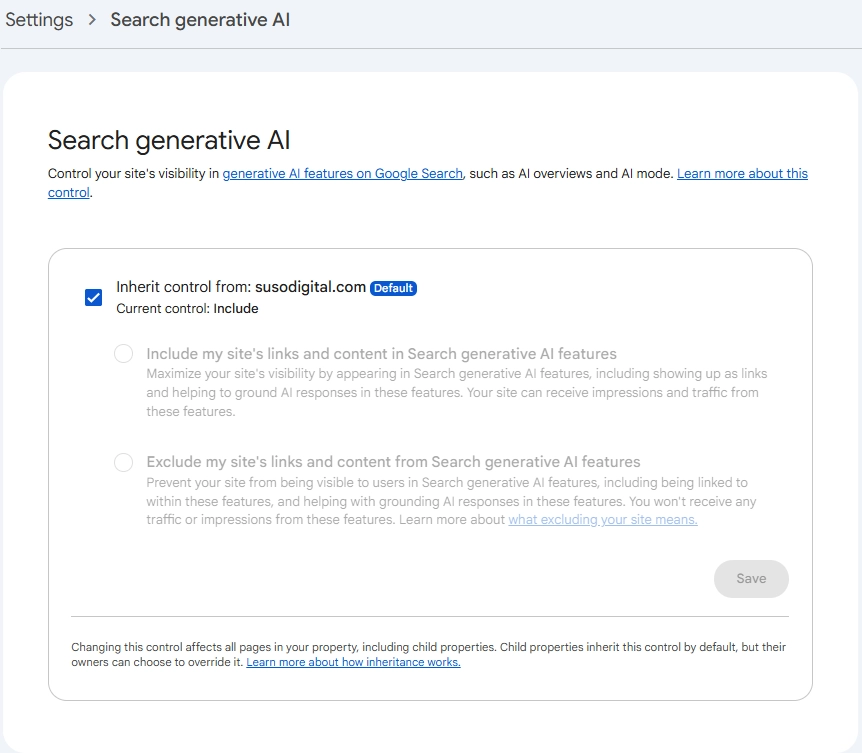
Google-Extended is a user-agent token you can add to your robots.txt to opt out of your content being used to train Gemini and Vertex AI. Critically, it does not affect your visibility in standard Google Search results. It also does not affect your appearance in AI Overviews or AI Mode. It is purely a training data opt-out.
AI Overviews and AI Mode are a different matter. Up until June 2026, there was no straightforward way to opt out of having your content featured in AI Overviews while remaining fully visible in standard search results.
In June 2026, the UK’s CMA ruled that publishers should be able to opt out of AI Overviews without search ranking penalties. Google confirmed it is rolling out the opt-out toggle globally, not just for the UK websites.
To check or change your website’s settings for controlling the visibility in Google’s AI search features, go to your Search Console property’s Settings -> AI Controls -> Search Generative AI.
The Risks of Blocking AI Bots
The argument against blocking AI bots is rooted in the fundamental principles of SEO and digital visibility.
Content Visibility and Discoverability are Paramount
The most significant reason to allow AI bots access is to ensure your content remains discoverable. Blocking AI bots means opting out of AI Overviews, featured snippets, and AI-generated summaries, which are the exact formats that are rapidly becoming the first thing users see. In a search landscape that is increasingly conversational and AI-driven, that’s a sure-fire way to lose market share.
Crucial Ranking Signals and a Complete SEO Picture
Search engines are continuously evolving their algorithms to understand user intent and content quality. Data gathered by their AI bots contributes to their overall understanding of your website.
By blocking these crawlers, you might be preventing search engines from getting a complete, holistic view of your content.
This could lead to a misinterpretation of your site’s authority, relevance, and overall value, potentially impacting your traditional organic rankings as well. In essence, you’re tying the hands of the very systems that are meant to promote your content.
Expanding Your Audience Reach Beyond Traditional Search
AI bots aren’t just about search results. They power voice assistants like Google Assistant and Alexa, personalized news feeds, and a myriad of other platforms. Your content, once indexed by these bots, has the potential to be distributed across this vast network. Blocking the bots that enable this distribution is a missed opportunity to connect with a wider, more diverse audience.
The Case for Blocking AI Bots
While we generally advise against blocking AI bots, we also acknowledge the legitimate concerns that fuel this debate.
Protecting Your Content from Unattributed Use
Many content creators’ primary concern is the fear of their work being scraped and used to train AI models without proper attribution or compensation. This is a valid and pressing issue in the digital age.
Server Performance and Traffic Management
In rare cases, a high volume of bot traffic can indeed strain server resources. However, it’s crucial to distinguish between legitimate, well-behaved bots and malicious ones. Reputable AI companies are typically mindful of server load and follow established crawl patterns.
If you’re experiencing performance issues, the solution is often not to block a legitimate bot but to optimize your website’s performance, improve your server infrastructure, or implement a content delivery network (CDN). Blocking a bot is a blunt instrument that often creates more problems than it solves.
Our Verdict: A Smart Strategy for the AI Age
SUSO’s verdict is clear: unless you have a specific technical reason, we generally advise against blocking legitimate AI bots. The SEO benefits of being indexed, discovered, and distributed by these tools far outweigh the potential risks and the limited effectiveness of blocking.
The question is no longer “should I block AI bots?” or “should I block AI training bots specifically?” It’s “which bots are actually reaching my site, and is that what I intended?”
Server-level blocks, CDN defaults, and hosting configurations have made this a technical verification problem as much as a strategic one. You can have the correct robots.txt directives in place and still be invisible to AI search, because the infrastructure you haven’t checked is enforcing its own rules. Standard SEO audits don’t catch this.
The future of search is intertwined with AI. Allow the right bots in, verify they’re actually getting through, and you’re positioned for the next generation of search.
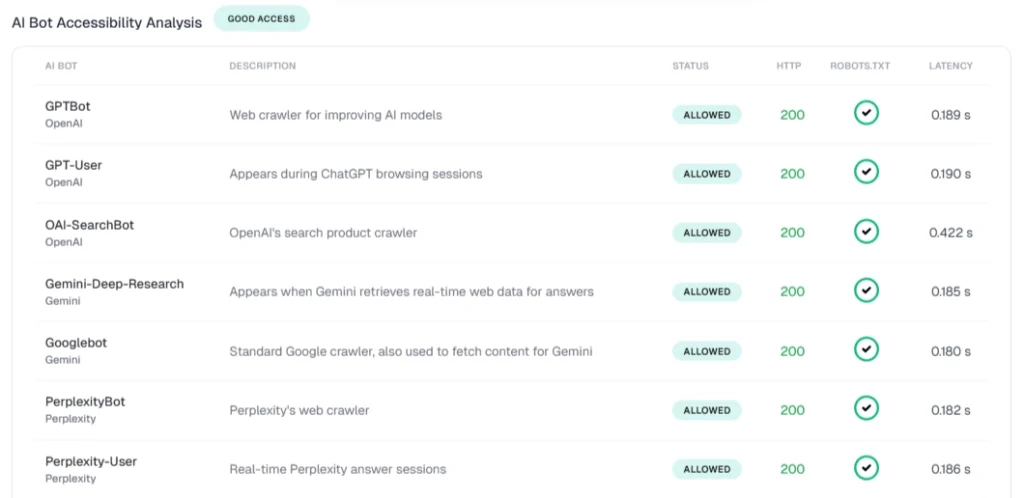
Is Your Site Invisible to AI Search?
Standard audits won’t tell you. Server-level blocks and CDN filters can cut you off from AI crawlers, leaving your robots.txt looking clean while bots receive a 403 they never report.
Use SUSO’s AI Search Visibility Checker to see exactly which bots can access your site, and fix it before your competitors do.
FAQs
-
Should I Block AI Training Bots?
Not necessarily. Training bots and retrieval bots serve different functions, and retrieval is what drives citations in AI responses, not training data. That said, the relationship between training data and what an LLM surfaces in knowledge-based answers isn’t fully transparent. The safer default is to stay crawlable. Before blocking anything, verify what each bot actually does
-
Should I Block GPTBot?
Only if you want to opt out of OpenAI’s training data. According to OpenAI’s documentation, GPTBot is for training, while a separate crawler, OAI-SearchBot, handles retrieval and citations in ChatGPT responses. Block OAI-SearchBot and you risk disappearing from ChatGPT’s search-based answers. Whether blocking GPTBot affects how your brand surfaces in knowledge-based (non-retrieval) responses is harder to say definitively: the relationship between training data and LLM outputs isn’t fully transparent. If content protection isn’t a pressing concern, leaving both crawlers allowed is the lower-risk approach.
-
Can I Opt Out of Google AI Overviews?
Yes, you can. In June 2026, due to regulatory pressure, it became possible to opt out of AI Overviews and Google’s AI Mode while staying visible in the traditional search results cleanly. The toggle now exists in Google Search Console, in the settings section.






