
Look under the hood of how Google’s web crawl Googlebot works and how you can control its crawl rate of your website.
Web crawlers may sound like futuristic villains from a science fiction movie, but they’re something we all encounter every day. Googlebot is just one type of web crawler, but it’s undoubtedly one of the best-known and most significant.
But what is Googlebot? How does it work? How much does it affect your website? I’ll answer all these questions (and a few others you may not have asked) in this comprehensive overview of Googlebot.
What is Googlebot?
Googlebot is the name of Google’s two web crawlers:
- Googlebot Desktop – which crawls the desktop version of a website
- Googlebot Smartphone – which crawls the mobile version of a website.
But that raises the question, “What is a web crawler?”
In the most basic terms, web crawlers, spiders, or bots are automated programs that crawl through thousands of websites to download content and store it in large databases.
These databases are crucial to a wide range of different functions, including the following:
- Data accumulation for analysis
- Website indexing
- Monitoring changes to websites
Googlebot is unique to Google and builds Google’s databases, making it an integral part of the indexing phase of SEO. Other search engines may use crawlers as well, but they’ll be separate from Google’s version.
These web crawlers analyse websites by following links and indicate what should be added to each search engine’s index. Of course, if you want optimum results, you need to ensure that your content is as easily accessible for Google’s crawler as possible.
How Does Googlebot Work?
Google has explained its indexing pipelines multiple times over the years, and the system generally remains fairly consistent. This illustration demonstrates one of the latest official pipelines:
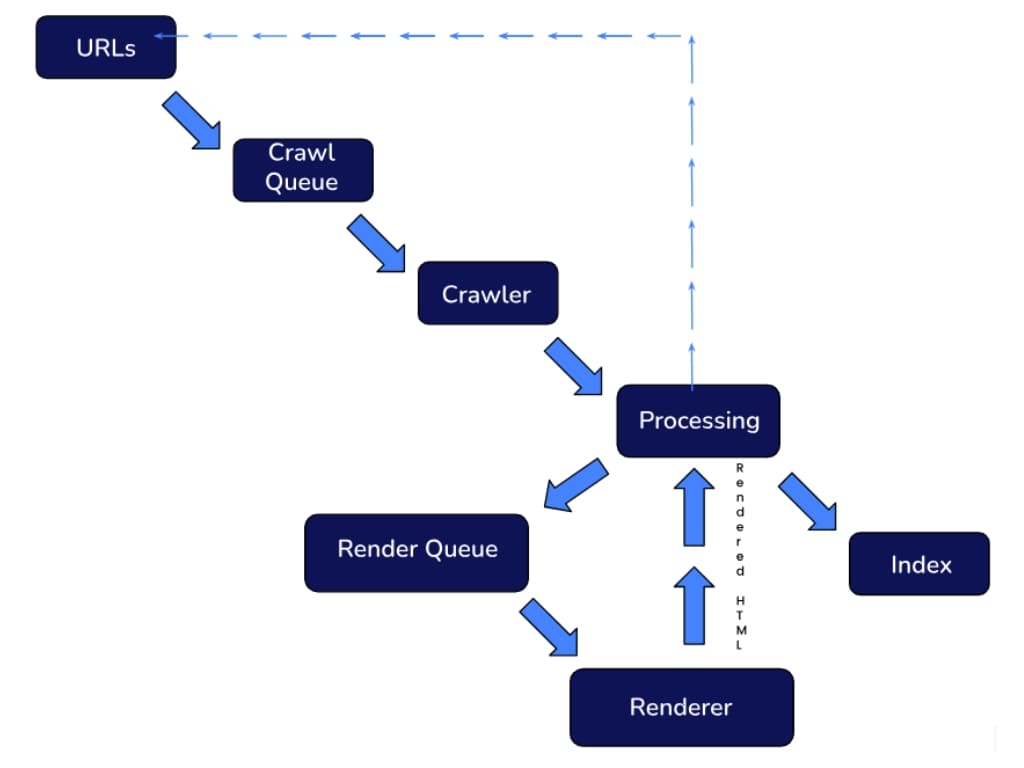
Googlebot regularly scans websites to look for new pages and links.
The rendered content is then stored in the database and indexed, allowing it to appear on Google search result pages based on Google’s ranking factors.
How to Control What Googlebot Crawls & Indexes
To get well on the way to mastering Google’s crawl of your website, you need to understand how you can control what the bot indexes. Fortunately, Google offers you several ways to do this.
Crawling
- Robots.txt – The robots.txt is a unique file on your website that allows you to limit what the Googlebot crawls.
- Nofollow – Pages marked as nofollow (whether as a link attribute or using a meta robots tag) suggest to the Googlebot that these pages shouldn’t be crawled. Using follow and nofollow tags is an essential part of internal linking.
- Crawl Rate Control – Using this tool in your Google Search Console, you can change the speed at which Googlebot crawls your website.
Indexing
- Content Deletion – Deleting content is a surefire way to ensure that Googlebot (and the rest of the known universe) can’t access or index a page.
- Restrict Content Access – If you protect a website (or specific webpage) with a password, it stops web crawlers, including Googlebot, from crawling that website.
- Use a Noindex Tag – Blocking unwanted resources using a noindex meta tag tells Googlebot and other web crawlers that a page shouldn’t be indexed. However, that doesn’t stop web crawlers from crawling the website.
- Use the URL Removal Tool – By using this tool on your Google Search Console, you can temporarily hide pages. Googlebot will still crawl them, but they won’t be indexed, so they won’t show up on search results.
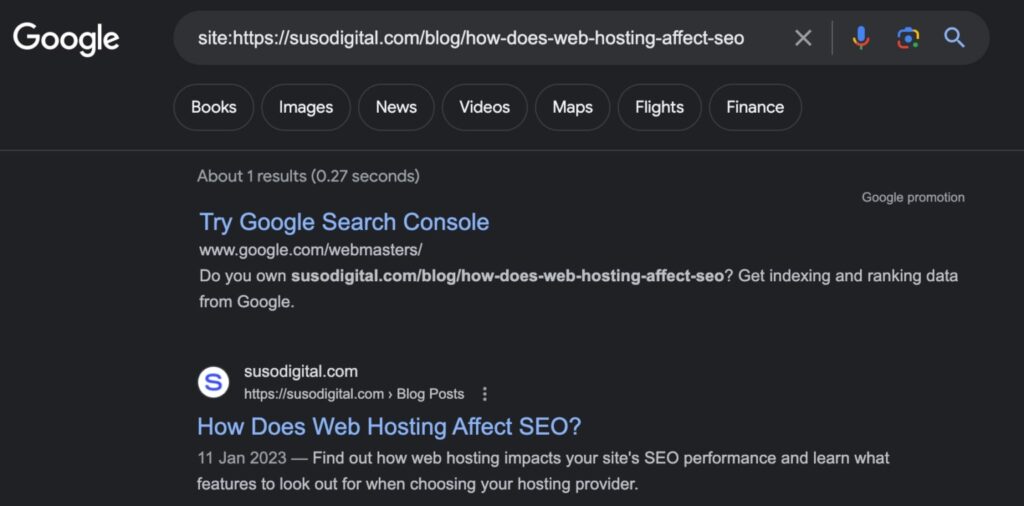
If you’re unsure as to whether your page has been indexed by Google, one quick way is to do a site search like: site:yourdomain.com/your-url
Here’s an example:
How to Verify Googlebot
There are many crawlers that pretend to be Googlebot in an aim to crawl your website. There are two possible verification methods you can use to ensure that the spider crawling your site is truly the Googlebot.
- Check your website logs to ensure that the requests your website is receiving are truly from Google. Thanks to Google’s handy list of public IP addresses, you can easily check if the IPs are related to Google or not.
- Visit your Google Search Console and check the Crawl Stats page to view the latest reports. This will quickly tell you how many times Googlebot has crawled your website recently.
Changing Googlebot’s Crawl Rate of Your Site
Googlebot is an integral part of maintaining a fully functional website. However, in certain cases, excessive crawling can lead to slow server functionality or availability issues.
If either of these things occurs, you need to know how to change Googlebot’s crawl rate for your website.
You can limit the crawl rate at any time by visiting the crawl rate settings page. However, if the page describes your crawl rate as “calculated as optimal,” you’ll need to file a special request to have it limited.
Under other circumstances, you can simply choose the crawl rate for your desired option and save the result. Your updated Googlebot crawl rate will remain valid for 90 days.
In the case of an emergency (such as a severely overcrawled website), you can practise emergency limitations. Here’s how:
- Determine which crawling agent is overloading your site by checking the website logs or crawl stats report.
- If you need immediate relief from the overcrawling, you can do one of two things:
- Use the robots.txt file to limit the offending crawler.
- Use a dynamic response to increased load, returning HTTP 503/429 when you’re nearing your serving limit.
Important: Both of these are temporary solutions, and using them for too long can result in the Googlebot permanently crawling your site less frequently. This can severely affect your website’s rankings and limit Google’s ability to index new content efficiently.
- If possible, change the crawl rate from the crawl rate settings page in your Google Search Console.
- Once the Googlebot has updated and is crawling your site less frequently (usually in about two or three days), you can remove the blocks or HTTP returns that you’ve used to limit the crawler
The Bottom Line
Googlebot is an essential part of life as a website owner as the crawlability of your site can have a significant impact on your site’s SEO performance. However, when problems arise with the accessibility of your content, you also need to know how to solve them.




