
Learn how to optimise your website’s crawl budget for SEO and ensure Google is able to crawl your most important pages.
Search engines don’t always crawl every page on a website straight away. As they have a fixed time and budget for how many pages their bots can and are willing to go over, the process may take long – even several weeks. This can get in the way of indexing your newly optimised landing pages.
To ensure your technical SEO efforts are effective, you should consider optimising your crawl budget, particularly if you have a large website with thousands of pages.
We’ve prepared a handy guide with tips to help you increase the frequency with which Google’s crawlers go over the pages on your site. Read on and learn about the key practices to nail your SEO game.
What is Crawl Budget?
Crawl budget is essentially the number of pages search engines will crawl on your website within a specific timeframe. In general, this number is relatively stable, although it may vary slightly from day to day.
Practically speaking, Google might crawl 5, 5,000 pages or even 15,000 pages every single day. Now, how is that number worked out? There are a few aspects that play a crucial role in establishing your site’s crawlability.
The number of pages Google crawls depends on several factors, such as the size of your website, its healthy performance (determined by how many errors Google encounters while crawling your site), and the number of links directed to your domain.
The good thing about those factors is that you are able to influence some of them in order to increase the number of your site’s pages that Google can and wants to crawl. So, how do you do that? Let’s get into it now.
8 Tips to Optimise Your Crawl Budget
Your domain’s crawl budget can fluctuate and is definitely not fixed. This means that there are some things you can do to manage your site’s crawlability.
Here are 8 valuable tips to improve the crawlability of your website.
Ensure Important Pages Aren’t Blocked By Your Robots.txt
Managing robots.txt is undoubtedly one of the most important steps to take when optimising your SEO crawl budget.
The robots.txt file (which you can usually access via yourdomain.com/robots.txt) is a file that allows you to block resources on your site that you do not want Google to crawl (and in turn index).
Here’s an example of what the SUSO Digital robots.txt file looks like:
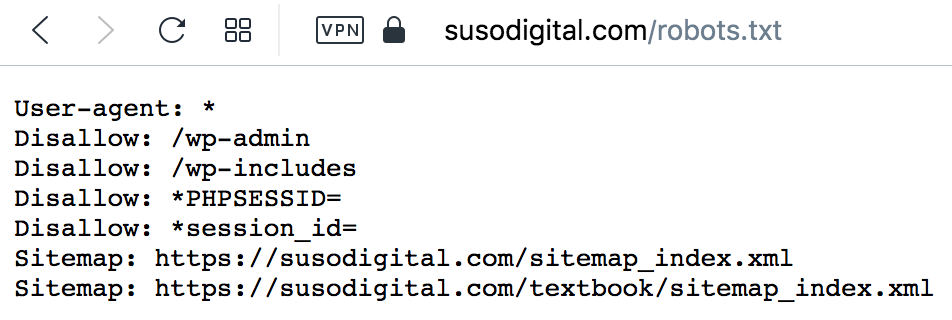
You want to make sure that you don’t accidentally block Google from accessing the most important pages on your website. For instance, the example below would block Googlebot from crawling all of our blog posts.
User-agent: *
Disallow: /blog/
Sitemap: https://susodigital.com/sitemap.xml
Learn more about the robots.txt file here You can also check to see if a page is blocked by your robots.txt file via the Robots Exclusion Checker Chrome extension.
Avoid Redirect Chains
Your website’s health highly depends on the number of redirect chains, or rather – the lack of them. Ideally, you would be able to avoid having even a single redirect chain on your entire website.
When dealing with very large sites – the appearance of 301 and 302 redirects is then inevitable and so reducing the number of redirect chains to an absolute zero may be difficult.
Multiple redirects chained together can significantly affect your crawl limit and even cause the search engine’s crawlers to stop going over your pages and not get to the page you want indexing.
Essentially, the idea is to pay attention to redirect chains on your site and keep them to a minimum. One or two redirects here and there might not harm your domain’s crawlability too much, but it’s crucial to have them under control.
Here’s what Google says about redirect chains:

You can spot redirect chains by auditing your website with a tool like Screaming Frog.
To fix redirect chains:
- Implement a 301 redirect from your old URL to the correct, destination URL.
- Importantly, remember to change any internal links that may be pointing to the old URL so that they now point to the new destination URL.
Doing this will help ensure that Google is easily able to crawl the destination URL.
Consolidate Duplicate Content
Duplicate content can damage your crawl budget. Why? Because search engines do not want to index multiple pages with the same content as it’s a waste of their resources.
That’s why making sure that your domain contains canonical URLs and that each of your website’s pages is made of unique, quality content is crucial for satisfying SEO results.
Although keeping all content unique on a site with thousands of pages might not always be easy, it’s one of the best practices to increase crawlability on your domain.
Improve Site Speed & Page Load Efficiency
Slow-loading pages impede the user’s experience and affect the number of organic visits, which as a result, leads to poor search rankings.
But they can also affect your crawl budget.
This is because Googlebot only has a certain amount of time to crawl your website – and if your pages take too long to load, fewer pages will be crawled.
Optimising your site speed is, therefore, vital for enhancing your site’s crawlability by allowing Googlebot to crawl as many pages as possible.
Check out our advanced guide about how to improve your site speed.
Eliminate Soft 404 Errors
Bad user experience is not only generated by slow site speeds but also by error pages that read “not found” after searching particular URLs. This also leads to poor crawlability of your website, as broken pages waste crawl budget.
Soft 404 errors may occur as a result of several factors. They might be caused by broken connections, unloaded or missing JavaScript files, or empty internal search result pages.
Identifying broken links (by using tools like Google Search Console) and eliminating errors is another important practice for improving your crawl budget.
Have a look at our article about handling 404 errors to learn about key methods for fixing them to guarantee the best SEO performance.
Use Internal Links to Improve Crawlability
Google’s crawlers will more likely go over pages that have many external and internal links pointing to them. For that reason, having internal linking in place is a key aspect of a successful SEO performance in terms of crawlability.
Using internal links on your pages is essential, but using them in a smart way is equally important.
The best strategy to implement internal linking is to add the links directed to your high-performing pages (or pages that are most important to you). This means you should focus on directing equity to those pages that target core keywords and therefore stand a good chance of ranking high.
This way, you will be able to maximise Google’s limited crawl budget and get the most out of it by elevating your already SEO-effective pages.
Update Your Sitemap
Googlebot crawls your XML sitemap on a regular basis.
It’s important to make it easier for them to understand where the internal links lead by using URLs that are canonical for your sitemap.
Including all the content you want the search engine to go over and keeping it up to date is crucial for a successful crawl budget optimisation. If your domain includes updated content, it’s recommended to use the <lastmod> tag.
Here’s an example of our sitemap:
In most cases, your XML sitemap can be found via the following URL: yourdomain.com/sitemap.xml.
Learn more about optimising your sitemap for Google here.
Avoid Orphan Pages
As you already know, pages with multiple internal links have better chances of getting indexed by Google crawlers. So what about pages that don’t include any internal links pointing to them? These are known as orphan pages, and it’s best to avoid them if you care about your crawl budget.
It’s pretty hard for search engines to find orphan pages, which ultimately results in poor crawlability. If you want to benefit from your crawl budget as much as possible, make sure there’s at least one internal or external link pointing to every page on your domain.
FAQs About Crawl Budget
-
How Does Google Calculate Crawl Budget?
Google’s crawl budget calculation is based on two factors – crawl rate, which means how often the bots can crawl a domain without issues, and crawl demand, which stands for how often they want to crawl a site.
Crawl rate is determined by domain authority, backlinks, crawl errors, site speed, and the number of landing pages. Larger sites usually feature higher crawl rates, while smaller or slower sites that have server errors and numerous redirects have lower crawlability.
Crawl demand tends to be higher for popular URLs as Google wants to provide the newest and freshest content for users. What’s more, higher demand is also observed among pages that haven’t been crawled for a long time. If your website goes through a site migration, Google will increase its crawl demand to update the index with new URLs.Check out our advanced guide about how to improve your site speed.Learn more about optimising your sitemap for Google here.
-
Is Crawl Budget Important For All Websites?
Crawl budget is particularly important for large websites, especially ‘unhealthy’ domains with multiple broken pages and redirects. For example, eCommerce sites that have thousands of pages can easily reach their crawl limit and are often negatively impacted by crawl budgets.
eCommerce sites, in particular, should pay close attention to how their crawl budgets operate due to their sizes, regular updates to their landing pages, and a tendency toward duplicate content (product pages and cookies).
The Bottom Line
Crawl budget optimisation is a valuable part of technical SEO. If your site is relatively small and well-maintained, it’s usually not something to worry about. However, large sites with thousands of pages, can considerably benefit from crawl budget optimisation.
Doing so can lead to better conversion rates and significant ranking improvements. Implementing appropriate practices in your SEO efforts will positively influence your site’s overall performance.




